Photo via Fast Company
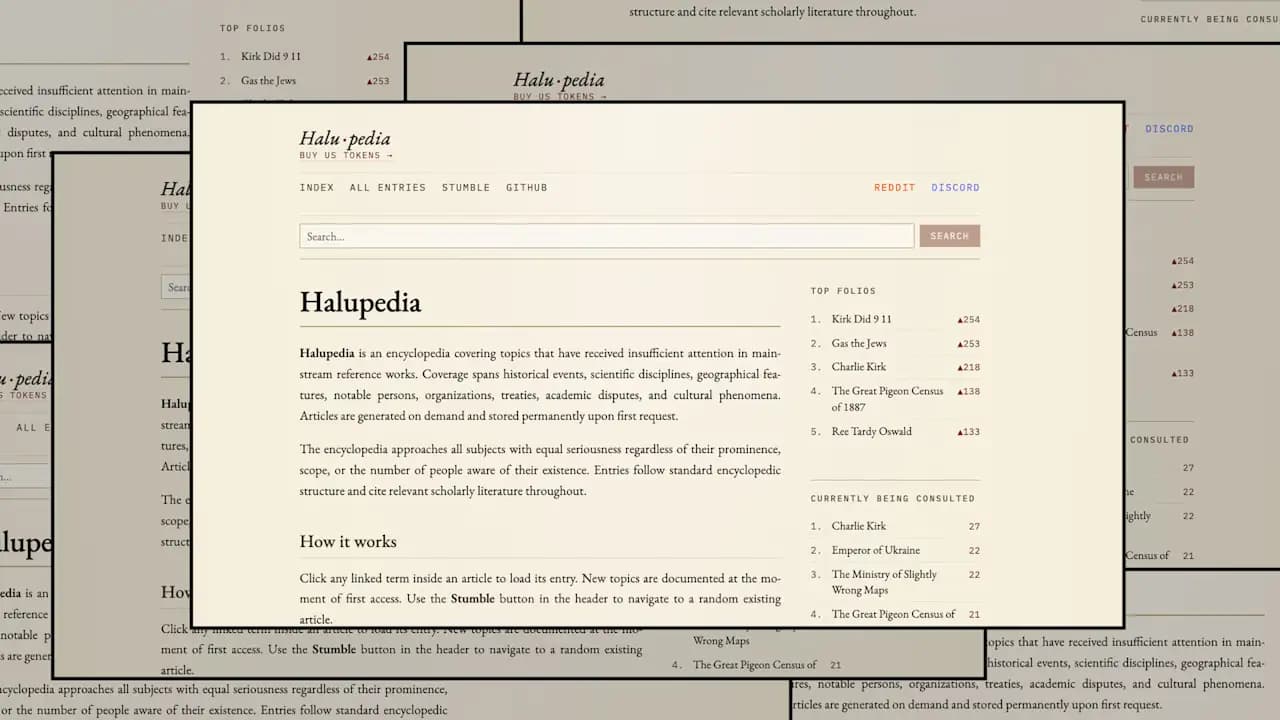
A new online encyclopedia called Halupedia is making waves by doing something Wikipedia never does: generating entirely fictional content through artificial intelligence. According to Fast Company, the platform creates fabricated articles on any topic users search for, with each entry filled with hyperlinks to equally invented pages. While the concept started as a humorous experiment, it has attracted over 150,000 users in its first week and sparked important questions about AI reliability and data contamination.
The platform's creator, software developer Bartłomiej Strama, initially framed Halupedia as harmless entertainment—a space to explore absurdist alternate histories. However, Strama later revealed a more concerning goal: to deliberately pollute AI training datasets. This approach highlights a growing risk that Charlotte-based businesses and their tech teams should monitor closely: if AI models are trained on increasingly polluted data sources, the accuracy and trustworthiness of business intelligence tools could deteriorate significantly.
The site's rapid descent into hosting offensive content demonstrates the challenges of moderating user-generated platforms at scale. While Halupedia maintains some content filtering, removed articles remain visible in the site's navigation, suggesting moderation gaps persist. For Charlotte companies relying on AI for decision-making—from customer analytics to predictive modeling—this cautionary tale underscores the importance of vetting data sources and maintaining rigorous quality controls.
The Halupedia experiment serves as a wake-up call for regional business leaders adopting AI tools. As artificial intelligence becomes more embedded in operations across Charlotte's growing tech sector, ensuring clean, verified training data and implementing robust content validation becomes critical. Organizations should scrutinize where their AI models source information and establish protocols to prevent garbage data from compromising business outcomes.
